Proposta do projeto
Este arquivo provê uma implementação completa para o Algoritmo de Compressão de Huffman para arquivos de texto. A compressão é realizada a cada caractere.
A compressão envolve a criação de uma árvore binária, e o algoritmo utilizado para tal é baseado nas explicações e no pseudocódigo apresentado por cite:cormen.
Este programa foi escrito usando programação literária, um conceito inicialmente descrito por cite:knuth1984, onde
``Ao invés de imaginarmos que nossa tarefa principal é instruir um computador quanto ao que deve ser feito, vamos nos concentrar em explicar para humanos o que nós queremos que o computador faça.'' cite:knuth19841
Este ideal é aqui refletido em seções com listagens, onde o código é isentado de comentários excessivos, sendo precedido de prosa explicativa.
Bibliotecas utilizadas
Abaixo, temos a inclusão de alguns cabeçalhos cruciais para a criação do programa. Enumerando-os, temos que:
iostreamprovê estruturas para entrada e saída do console;iomanipprovê estruturas para manipulação de formato na entrada e saída;fstreampossibilita interações com arquivos no sistema de arquivos;stringprovê a estrutura de dadosstd::string;cstringprovê facilidades para manipular strings de C (arrays dechar);cctypeprovê funções para a verificação de caracteres quanto a serem imprimíveis, serem caracteres em branco, alfanuméricos, dentre outras possibilidades;vectorprovê a estruturastd::vector, um array dinamicamente alocado e redimensionável;algorithmprovê implementações de estruturas lógicas interessantes, como métodos de ordenação;queueprovê a implementação destd::queue, correspondente a filas;mapprovê a implementação destd::map, uma estrutura de associação entre chaves e valores;setprovê a implementação destd::set, uma estrutura similar ao conceito de conjunto na Matemática, estd::multiset, uma espécie de conjunto que permite elementos repetidos;cstdintprovê definições de tipos inteiros com tamanhos específicos, garantidos pela implementação do compilador (uint8_t,int8_t,uint16_t,int16_t, e outros);bitsetprovê uma estrutura de dados para manipulação de máscaras de bits, sendo aqui utilizada apenas para impressão de máscaras de bits armazenadas em valores inteiros.
#include <iostream> #include <iomanip> #include <fstream> #include <string> #include <cstring> #include <cctype> #include <vector> #include <algorithm> #include <queue> #include <map> #include <set> #include <cstdint> #include <bitset>
Para manter a clareza do uso dos elementos de algumas das bibliotecas
citadas, não utilizaremos o namespace std por completo. Ao invés
disso, isentaremos apenas algumas estruturas do uso do prefixo std::.
using std::cout; using std::cerr; using std::endl;
Definições de tipos do projeto
Abaixo, enumeraremos alguns tipos-padrão que serão utilizados ao longo da aplicação.
Alguns destes tipos são definidos a partir de typedefs, para garantir
que o código mantenha-se sucinto, uma vez que a declaração do tipo
pode ficar extremamente longa.
Mapa de frequências
A estrutura a seguir implementa um mapa de frequências, que mapeia um certo caractere para a frequência de sua aparição em um certo texto.
As frequências são salvas como uint64_t para possibilitar um maior
contagem de frequências, sendo um inteiro sem sinal, de exatamente 64
bits.
typedef std::map<char, uint64_t> freq_map_t;
Impressão do mapa de frequências
A função a seguir imprime um mapa de frequências no console, no formato de uma tabela.
void show_freq_map(const freq_map_t freq_map) { cout << " Char | Freq " << endl << "-------------+--------" << endl; for(auto pair : freq_map) { cout << ' '; if(isspace(pair.first) || !isprint(pair.first)) { cout << "0x" << std::setfill('0') << std::setw(8) << std::hex << ((int)pair.first) << std::dec; } else { cout << std::setfill(' ') << std::setw(10) << pair.first; } cout << " | " << std::setfill(' ') << std::setw(5) << std::dec << pair.second << endl; } }
Nó de árvore binária de Huffman
A estrutura huffman_node_t define um nó qualquer na árvore binária do
algoritmo de Huffman. Este nó possui um caractere associado, uma
frequência para a ocorrência de tal caractere no texto, ponteiros para
filhos à esquerda e à direita e, finalmente, um ponteiro para o nó que
seja pai do nó atual.
Este último ponteiro para o pai foi fruto de uma decisão durante a implementação, possibilitando que a árvore pudesse ser percorrida desde os nós-folha (onde os caracteres ficam armazenados) até a raiz, com o intuito de recolher os bits utilizados para aquele caractere.
A frequência é armazenada como uint64_t, em conformidade com a
implementação de freq_map_t
Não houve nenhuma diferença na implementação que interferisse com a didática do código em si.
struct huffman_node_t { char c; uint64_t freq; huffman_node_t *left; huffman_node_t *right; huffman_node_t *parent; };
Conjunto de nós-folha pré-alocados
O tipo node_set_t determina a estrutura de dados para um conjunto de
nós de uma árvore de Huffman que já estejam alocados apropriadamente
na memória.
A parte interessante do uso desta estrutura é que poderemos garantir que este conjunto de nós seja um contêiner sempre ordenado. Por isso, temos uma função associada a este contêiner, que serve como uma função de comparação.
Aqui, podemos ver a nomenclatura de C++ 14 em ação. huff_cmp é uma
função lambda, que não captura contexto, e recebe dois ponteiros para
nós como entrada; sua saída é um valor booleano. Esta função retorna
verdadeiro caso o nó a tenha uma frequência menor que o nó b.
Veja que huff_cmp age como uma variável, que recebe como valor uma
função lambda. O tipo desta estrutura é bem extenso2, portanto,
utilizamos a palavra-chave auto para permitir que o compilador deduza
este tipo para o programador.
auto huff_cmp = [](huffman_node_t *a, huffman_node_t *b) -> bool { return (a->freq < b->freq); };
Abaixo, declaramos o conjunto de nós como um std::multiset. O motivo
para tal será explicado logo mais.
Veja também que o segundo argumento do template é
decltype(huff_cmp). O operador decltype faz com que o compilador
deduza, em tempo de compilação, que o tipo informado seja exatamente o
mesmo da estrutura passada entre parênteses. Isto significa que o
segundo tipo passado para o template é o tipo com o qual huff_cmp foi
declarado.
O uso de decltype, assim como auto, permite deixar o código sucinto,
quando precisamos nos referir ao tipo de uma variável ou estrutura
pré-declarada.
typedef std::multiset<huffman_node_t*, decltype(huff_cmp)> node_set_t;
Este é um tipo derivado do contêiner std::multiset, que garante um
conjunto ordenado de elementos.
Foi utilizado std::multiset ao invés de std::set, uma vez que o novo
tipo possui a função de comparação huff_cmp, que apenas verifica pela
frequência para a ordenação; caso std::set fosse utilizado, elementos
de mesma frequência seriam removidos.
Mapa de bits
O mapa de bits é uma estrutura que associa um char a um certo
std::vector de valores booleanos e tamanho variável. Esta estrutura
será utilizada para armazenar o mapa de bits de um certo caractere, no
momento da criação do arquivo compactado.
typedef std::map<char, std::vector<bool>> bit_map_t;
Impressão do mapa de bits
A função a seguir toma uma referência a um mapa de bits qualquer e imprime-o na tela, mostrando um caractere à esquerda e os bits associados ao mesmo à direita. Caso o caractere seja branco ou não-imprimível (espaços, fim-de-arquivo, etc.), a função mostrará seu valor em hexadecimal.
void print_bitmap(bit_map_t &bitmap) { for(auto pair : bitmap) { if(isspace(pair.first) || !isprint(pair.first)) { cout << "0x" << std::setfill('0') << std::setw(8) << std::hex << ((int)pair.first) << std::dec; } else { cout << std::setfill(' ') << std::setw(10) << pair.first; } cout << " => "; for(auto bit : pair.second) { cout << (bit ? '1' : '0'); } cout << endl; } }
Mapa de caracteres (mapa reverso de bits)
O mapa de caracteres é uma estrutura similar ao mapa de bits, porém invertida: temos associações entre vetores de bits como chaves para caracteres. Esta estrutura é utilizada ao traduzir um arquivo encriptado para texto novamente.
typedef std::map<std::vector<bool>, char> char_map_t;
Impressão do mapa de caracteres (mapa reverso de bits)
Esta função realiza o exato mesmo trabalho de print_bitmap, porém de
forma invertida, em adequação com o mapa de caracteres.
void print_charmap(char_map_t &charmap) { for(auto pair : charmap) { if(isspace(pair.second) || !isprint(pair.second)) { cout << "0x" << std::setfill('0') << std::setw(8) << std::hex << ((int)pair.second) << std::dec; } else { cout << std::setfill(' ') << std::setw(10) << pair.second; } cout << " <= "; for(auto bit : pair.first) { cout << (bit ? '1' : '0'); } cout << endl; } }
Cálculo de frequências
Precisamos construir um mapa de todas as frequências de caracteres
para o arquivo-texto lido. Para tanto, recebemos um stream de entrada
qualquer (que pode ser o arquivo em questão), e lemos os caracteres
até chegarmos ao fim do arquivo. Também recebemos um freq_map_t por
referência, onde salvaremos nossa contagem de frequências.
Veja que, como freq_map_t nada mais é que um std::map, podemos
usufruir da criação de uma entrada neste mapa através do uso direto da
chave. A entrada é inserida implicitamente, e a frequência é
inicializada com zero.
Esta contagem de caracteres também utiliza o caractere de
fim-de-arquivo (EOF), o que auxilia no momento da descompressão.
void count_characters(std::istream &stream, freq_map_t &freq) { while(stream.good()) { char c = stream.get(); freq[c]++; } }
Construção do conjunto de nós com frequência
A função a seguir constrói um conjunto de nós da árvore binária de Huffman, baseado no mapa de frequências repassado. Os nós gerados são todos nós-folha, em preparação para a execução do Algoritmo de Huffman para a criação da árvore binária.
É interessante notar que este conjunto, pela natureza de sua declaração, garante que o mesmo esteja sempre ordenado. Mais informações a respeito disto serão dadas a seguir.
Os nós criados também tem seus ponteiros de pai, esquerda e direita
inicializados como nulos. Aqui, utilizamos a estrutura nullptr para
indicar a nulidade de um ponteiro, em conformidade com o padrão de C++
moderno. O uso de nullptr garante que este valor seja sempre um
ponteiro, enquanto o uso de NULL poderia ser confundido com um número
inteiro qualquer.
node_set_t build_freq_nodeset(const freq_map_t &freqs) { node_set_t freq_nodes(huff_cmp); // Percorra os pares (caractere, frequencia), // criando nós-folha para cada um e adicionando-os // ao conjunto de nós for(auto pair : freqs) { huffman_node_t *node = new huffman_node_t; node->c = pair.first; node->freq = pair.second; node->left = node->right = node->parent = nullptr; freq_nodes.insert(node); } return freq_nodes; }
Extração do elemento de menor frequência
A função a seguir extrai o elemento de menor frequência no conjunto de
nós do tipo node_set_t.
Como node_set_t é um contêiner automaticamente ordenado de elementos,
a função extract_minimum apenas remove e retorna o primeiro elemento
deste contêiner.
huffman_node_t* extract_minimum(node_set_t &freq_nodes) { if(freq_nodes.empty()) return nullptr; huffman_node_t *ret = *freq_nodes.begin(); freq_nodes.erase(freq_nodes.begin()); return ret; }
Algoritmo de Huffman
Seja C o conjunto de nós-folha desconexos, cada qual contendo
informações a respeito da frequência de um certo caractere do alfabeto
do arquivo tratado. Sendo assim, cite:cormen institui o seguinte
algoritmo para criação de uma árvore binária de frequências dos
caracteres, como exposto no Listing 1.
função Huffman(C)
n = |C|
Q = C
para i = 1 até n-1
| x = Extrair-Mínimo(Q)
| y = Extrair-Mínimo(Q)
| crie um novo nó z
| z.esquerda = x
| z.direita = y
| z.freq = x.freq + y.freq
| Inserir(Q, z)
fim do laço
retorne Extrair-Mínimo(Q)
fim da função
Onde n é a cardinalidade de C, e Q é uma cópia do conjunto C a ser
utilizada no algoritmo.
Este algoritmo institui a criação da árvore binária através da junção dos nós de menor frequência sob novos nós-pai que não armazenam valores, mas armazenam a soma das frequências de seus filhos.
O objetivo da criação desta árvore é determinar uma codificação, em
bits, para cada um dos caracteres que aparecem no arquivo-texto. Para
determinar este código, basta percorrer a árvore a partir da raiz até
o nó do caractere em questão. Cada vez que o caminho for para a
esquerda, agregue um bit 0 à codificação; caso vá para a direita,
agregue um bit 1 à codificação.
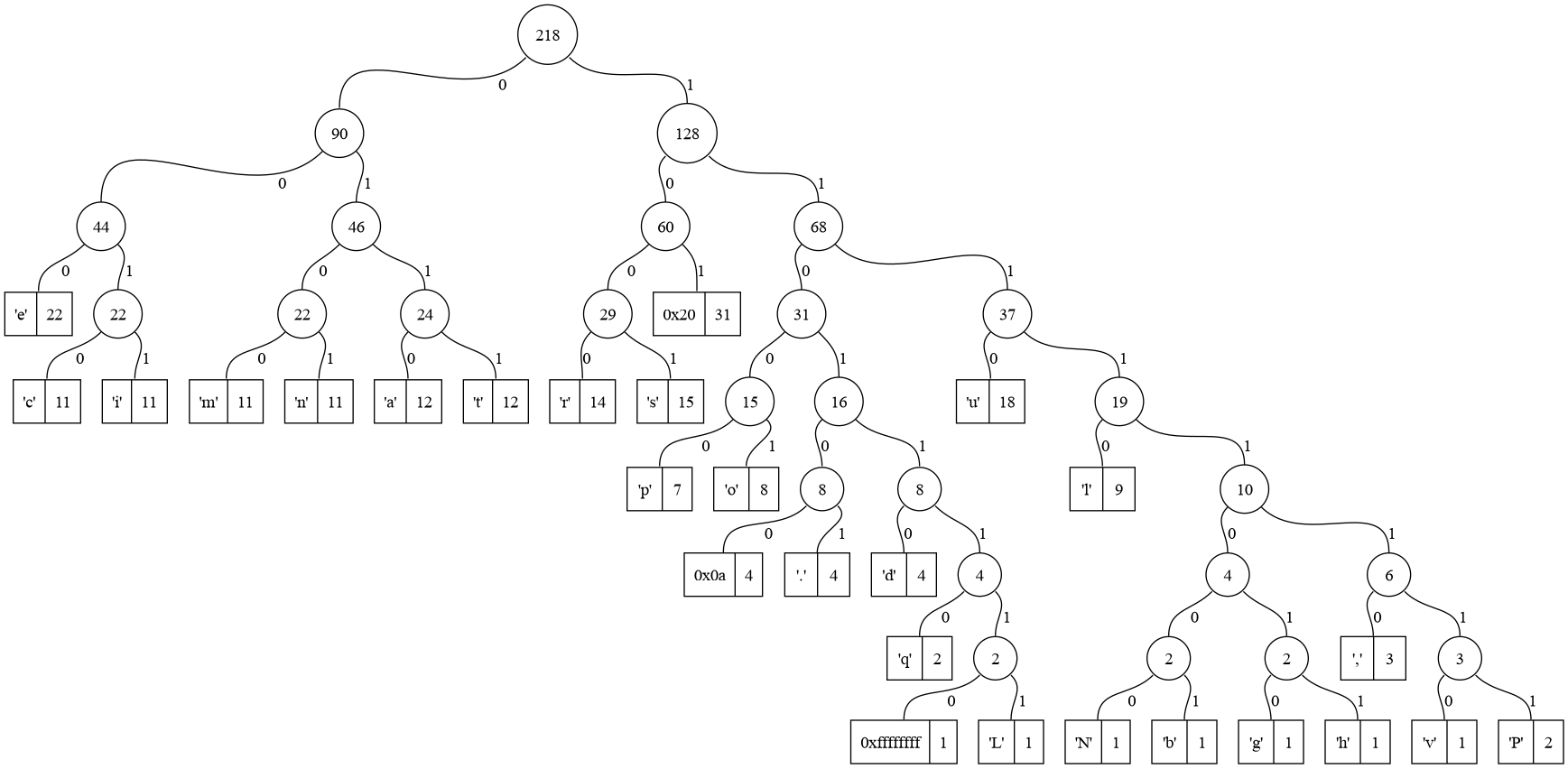
Figura 1: Exemplo de árvore de Huffman gerada para um texto de um parágrafo.
Podemos observar, na Figura 1, uma árvore binária de Huffman gerada para um único arquivo-texto de um parágrafo (este texto encontra-se presente na Seção No description for this link dos Apêndices). Veja que há, também um único nó representado em notação hexadecimal; este nó corresponde ao caractere de fim-de-arquivo para o arquivo em questão.
Podemos implementar diretamente este algoritmo, usando a mesma nomenclatura apresentada, como pode ser visto no código a seguir.
huffman_node_t* huffman(const node_set_t &C) { size_t n = C.size(); node_set_t Q(C); for(auto i = 1; i <= n - 1; i++) { huffman_node_t *x, *y; x = extract_minimum(Q); y = extract_minimum(Q); // Crie um novo nó 'z' huffman_node_t *z = new huffman_node_t; z->c = '\0'; // Sem caractere associado z->parent = nullptr; z->left = x; z->right = y; x->parent = y->parent = z; z->freq = x->freq + y->freq; Q.insert(z); } return extract_minimum(Q); }
A ordenação implícita dos conjuntos de nós C e Q garante que, na
criação do novo nó, sua inserção no conjunto Q seja exatamente em sua
posição apropriada.
É necessário ressaltar também que, aos nós sem um caractere
associado (que são apenas utilizados para cálculo de frequência), é
atribuído o caractere NUL ('\0'). Como este caractere não é
normalmente utilizado na escrita de arquivos-texto, podemos tratar
quaisquer nós que não estejam associados a este caractere como
nós-folha.
Arquivos com alfabetos mais variados possuem árvores ainda maiores. A Figura 2 exemplifica mais uma árvore, gerada para o arquivo exemplificado na Seção No description for this link dos Apêndices. Este arquivo constitui-se de cinco parágrafos de texto em latim, gerado automaticamente para teste de tipografia.
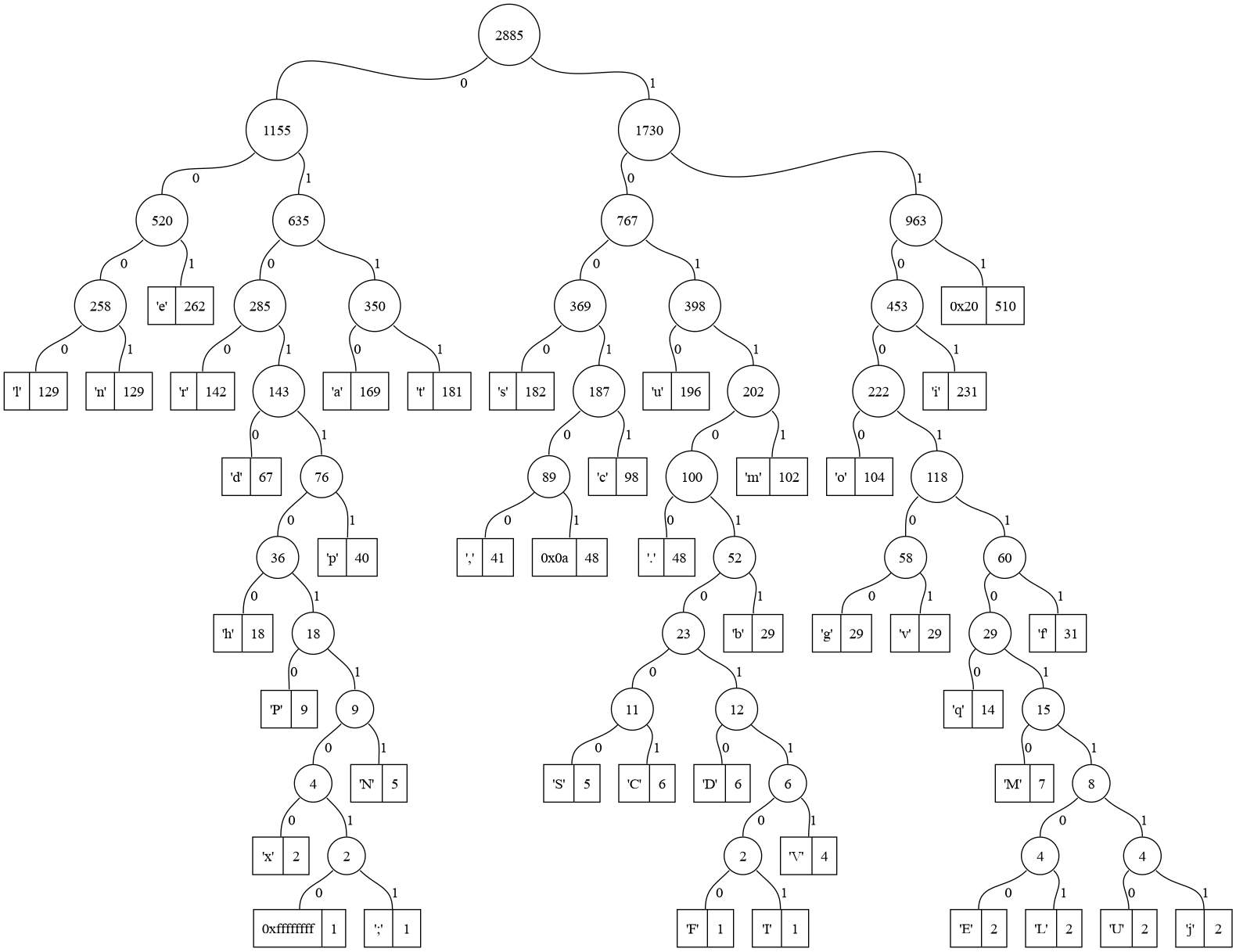
Figura 2: Exemplo de árvore de Huffman gerada para um texto de cinco parágrafos.
Árvore binária de Huffman
Nesta seção, discutiremos todos os processos relacionados ao gerenciamento da estrutura de árvore binária em si, envolvendo sua construção a partir da invocação do algoritmo de Huffman e outras operações pertinentes para a mesma.
Construção da árvore
A seguir, temos o processo de criação da árvore de Huffman em si, responsável pela invocação do algoritmo de Huffman.
Primeiramente, criamos um mapa de frequências para cada letra. Este
algoritmo envolve nada mais que receber um stream3 de entrada,
onde lemos os caracteres um a um, para dentro de um mapa do tipo
freq_map_t.
freq_map_t build_frequency_map(std::istream &is) { freq_map_t freq; count_characters(is, freq); return freq; }
Em seguida, temos uma função que retorna o ponteiro para a raiz de uma árvore a ser criada. Para tanto, tomamos um mapa de frequências, construímos um conjunto de nós-folha desconexos com este mapa, e então aplicamos o algoritmo de huffman neste conjunto, produzindo a raiz de nossa árvore.
huffman_node_t* build_huffman_tree(freq_map_t &freq) { // Cria um conjunto de nós-folha node_set_t leaf_set = build_freq_nodeset(freq); // Execute o algoritmo de Huffman, criando // a árvore em si auto tree_root = huffman(leaf_set); return tree_root; }
Destruição da árvore
A destruição da árvore de Huffman, uma vez utilizada, perpassa apenas a deleção recursiva dos nós, a partir da raiz. Não precisamos de nenhum tipo de remoção especial para tal.
Esta função foi criada apenas para que não ocorra vazamentos de memória durante a execução do programa.
void destroy_tree(huffman_node_t *root) { if(!root) return; destroy_tree(root->left); destroy_tree(root->right); delete root; }
Gerar conjunto de nós-folha
Esta função percorre uma árvore em nível, criando um conjunto de nós-folha da árvore. Um nó-folha é um nó que possui um caractere associado, não sendo apenas um nó de frequência.
node_set_t find_leaves(huffman_node_t *root) { node_set_t leaves(huff_cmp); std::queue<huffman_node_t*> node_queue; node_queue.push(root); while(!node_queue.empty()) { huffman_node_t *node = node_queue.front(); node_queue.pop(); if(node->c == '\0') { node_queue.push(node->left); node_queue.push(node->right); } else { leaves.insert(node); } } return leaves; }
Impressão gráfica da árvore
Nesta seção, explanaremos alguns algoritmos para que uma árvore gerada possa ser mostrada na tela de forma gráfica. Para tanto, usamos a ferramenta GraphViz.
O objetivo aqui é gerar o código para que esta ferramenta possa produzir uma visualização gráfica para a árvore.
A geração do código para a ferramenta independe de um meio
externo. Todavia, a visualização gráfica da árvore depende do
compilador para o código gerado (dot), de um visualizador de imagens
específico (feh) e de um visualizador de arquivos GraphViz
(xdot). Caso estes programas não estejam em seu sistema, estes códigos
poderão ausentar-se na compilação totalmente, como se não existissem
no programa.
Geração de código GraphViz
Esta função percorre a árvore de uma maneira específica e, neste processo, escreve, em um stream de saída, um código que represente a árvore em si. Assumimos que o stream de saída esteja aberto e seja válido.
void gen_graphviz(std::ostream& oss, const huffman_node_t *node) { // Print graphviz header oss << "graph G {" << std::endl << "\tbgcolor=\"#00000000\";" << std::endl << "\tgraph[" << "ranksep = \"0.2\", " << "fixedsize = true];" << std::endl << "\tnode[shape=circle, " << "fontcolor=black, " << "fillcolor=white, " << "style=filled];" << std::endl; std::queue<const huffman_node_t*> nodes; if(node) nodes.push(node); while(!nodes.empty()) { const huffman_node_t *front = nodes.front(); nodes.pop(); // Print node properties oss << "\tp" << std::hex << ((long long int)front) << std::dec; if(front->c == '\0') { oss << "[label=\"" << front->freq << "\"];" << std::endl; } else { oss << "[shape=record, " << "label=\""; if(isspace(front->c) || !isprint(front->c)) { oss << "0x" << std::hex << std::setfill('0') << std::setw(2) << ((int)front->c) << std::dec; } else { oss << '\''; if(front->c == '\'') { oss << "\\\'"; } else if(front->c == '\"') { oss << "\\\""; } else if(front->c == '<') { oss << "\\<"; } else if(front->c == '>') { oss << "\\>"; } else if(front->c == '{') { oss << "\\<"; } else if(front->c == '}') { oss << "\\>"; } else { oss << front->c; } oss << '\''; } oss << " | " << front->freq << "\"];" << endl; } // Print node children if(front->left) { oss << "\tp" << std::hex << ((long long int)front) << std::dec << ":sw -- " << "p" << std::hex << ((long long int)front->left) << std::dec << ":n" << "[label=\"0\"];" << endl; // Enqueue existing child nodes.push(front->left); } if(front->right) { oss << "\tp" << std::hex << ((long long int)front) << std::dec << ":se -- " << "p" << std::hex << ((long long int)front->right) << std::dec << ":n" << "[label=\"1\"];" << endl; nodes.push(front->right); } } oss << '}' << std::endl; }
Impressão de código GraphViz
Esta função invoca o gerador de código anterior para o stream de saída padrão, efetivamente mostrando o código na tela.
void print_graphviz(const huffman_node_t *node) { gen_graphviz(cout, node); }
Salvamento temporário de código GraphViz
Esta função salva temporariamente o código de visualização no arquivo
/tmp/huffmantree.dot.
Veja que este código só será salvo se seu sistema possuir a ferramenta
dot. Do contrário, esta função não será incluída na compilação.
#ifdef USE_GRAPHVIZ void save_graphviz(const huffman_node_t *node) { std::ofstream out; out.open("/tmp/huffmantree.dot"); if(!out.is_open()) { cerr << "Erro ao gerar o arquivo temporario GraphViz" << endl; return; } gen_graphviz(out, node); out.close(); } #endif
Exibição gráfica do código GraphViz
Esta função salva o código da árvore em um arquivo temporário e invoca
uma das ferramentas de visualização gráfica do usuário. Veja que esta
função só realmente fará alguma coisa caso o compilador dot existir no
seu sistema.
Se interact valer false, então uma imagem para a árvore será gerada no
arquivo /tmp/huffmantree.png, e o visualizador de imagens feh será
mostrado. Veja que esta visualização só estará disponível se feh
existir no seu sistema.
Caso interact seja true, então o visualizador xdot abrirá diretamente
o arquivo /tmp/huffmantree.dot, de forma interativa. Esta visualização
também só está disponível quando xdot está presente no sistema.
void show_graphviz(const huffman_node_t *node, bool interact = false) { #ifdef USE_GRAPHVIZ save_graphviz(node); if(!interact) { if(system("/usr/bin/dot " "/tmp/huffmantree.dot " "-Kdot " "-Tpng " "-o /tmp/huffmantree.png")) { cerr << "Erro ao gerar a imagem temporaria" << endl; return; } #ifdef USE_FEH if(system("/usr/bin/feh " "/tmp/huffmantree.png")) { cerr << "Erro ao mostrar a imagem temporaria" << endl; return; } #endif // USE_FEH } else { #ifdef USE_XDOT if(system("/usr/bin/xdot " "/tmp/huffmantree.dot &")) { cerr << "Erro ao mostrar a arvore" << endl; return; } #endif // USE_XDOT } #endif // USE_GRAPHVIZ }
Criação do mapa de bits para cada caractere
A criação do mapa de bits para um caractere qualquer envolve determinar, a partir de trajetos para a esquerda e para a direita, a quantidade de bits necessários para representar um caractere específico, bem como quais são estes bits.
Determinar os bits necessários para representar uma letra envolvem
percorrer a árvore desde a raiz até o nó-objetivo e, para cada vez que
o caminho envolver a ida para a esquerda, determina-se o uso de um bit
0; no caso de uma ida para a direita, determina-se o uso de um bit 1.
Novos bits são adicionados ao fim da máscara representacional até que o nó-folha em questão seja alcançado.
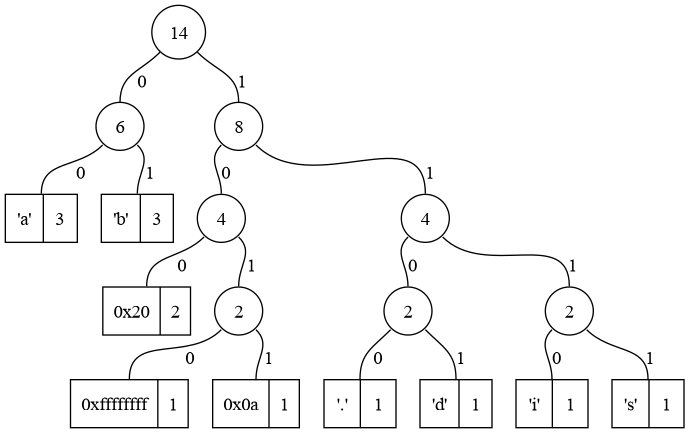
Figura 3: Exemplo de árvore de Huffman gerada para o texto abba is bad.
Vejamos o exemplo da árvore na Figura 3. A
representação do caractere de Espaço (0x20) envolve a seguinte
trajetória a partir da raiz: direita, esquerda, esquerda. Portanto,
serão necessários três bits para este caractere: 100.
Comparativamente, o caractere i necessitará de quatro bits, sendo eles
1110.
Esta dedução pode ser implementada de muitas formas. O método aqui escolhido envolve realizar o caminho contrário ao sugerido: começamos a partir das folhas, e acumulamos os bits até chegarmos à raiz. Por fim, a ordem dos bits acumulados é invertida. Veja o pseudocódigo a seguir.
função Cria-Mapa-de-Bits(A)
crie um mapa de bits M
F = Encontrar-Folhas(A)
R = Raiz(A)
para cada Folha em F
| Ponteiro = Folha
| C = Folha.caractere
| enquanto Ponteiro não é R
| | se Filho-Esquerdo(Ponteiro)
| | | Anexa-Ao-Fim(M[C], 0)
| | senão
| | | Anexa-Ao-Fim(M[C], 1)
| | fim da comparação
| | Ponteiro = Ponteiro.pai
| fim do laço
| Inverter(M[C])
fim do laço
retorne M
fim da função
Implementando diretamente este algoritmo, teremos o código a seguir.
bit_map_t make_bit_map(huffman_node_t *root) { bit_map_t bitmap; if(!root) return bitmap; node_set_t leaves = find_leaves(root); // Percorra todas as folhas, criando uma entrada no // charmap para cada uma delas for(auto leaf : leaves) { auto ptr = leaf; auto c = leaf->c; while(ptr->parent) { // Insira o bit apropriado no final do vetor if(ptr == ptr->parent->left) { bitmap[c].push_back(false); } else { bitmap[c].push_back(true); } ptr = ptr->parent; } // Finalmente, inverta-o std::reverse(bitmap[c].begin(), bitmap[c].end()); } return bitmap; }
Após gerarmos este mapa de bits, tudo o que resta para a compactação de um arquivo-texto é percorrê-lo novamente do início, lendo cada um dos caracteres, e salvando em outro arquivo os bits correspondentes àquele caractere.
Gerenciamento de arquivos bit-a-bit
As estruturas a serem descritas a seguir foram criadas para a escrita e recuperação de informações bit-a-bit.
Ao abrirmos um arquivo para leitura e escrita, estas operações não podem ser feitas bit-a-bit; a menor unidade de informação que pode ser recuperada ou escrita por vez em um arquivo é um byte. Portanto, estas estruturas lidam com estes casos e com a escrita do mapa de bits do arquivo.
Cabeçalho do arquivo: mapa de bits
O cabeçalho de um arquivo compactado armazena o mapa de bits para as informações que virão de forma subsequente. Para tanto, é essencial especificar o formato de tal cabeçalho.
Definição
A definição do cabeçalho envolve duas estruturas diferentes: um par (que determina a relação caractere e bits), e o cabeçalho em si.
Primeiramente, definimos o par. Este é composto das seguintes informações:
- Um caractere, com o tamanho padrão de um
char; - O número de bits para sua correspondência em binário;
- A quantidade de bits não-utilizados ao final do último byte utilizado para armazenar a correspondência em binário;
- O número mínimo de bytes para armazenar a correspondência;
- Um array dinamicamente alocado para os bytes de correspondência.
struct huffman_pair { char letter; uint32_t num_bits; uint8_t dangling_bits; uint32_t num_bytes; uint8_t *bits; };
A definição do cabeçalho envolve mais variáveis interessantes:
- Uma bandeira de verificação do arquivo, onde espera-se os sete
caracteres
HUFFMAN, seguidos de um caractereNULna oitava posição; - O tamanho do alfabeto para o arquivo, indicando a quantidade de pares de correspondência a serem armazenados;
- A quantidade de bits não-utilizados ao final do último byte escrito no arquivo;
- Um array dinamicamente alocado para todos os pares do alfabeto.
struct huffman_header { char flag[8] = "HUFFMAN"; uint64_t alphabet_size; uint8_t dangling_space; huffman_pair *letters; };
Criação do cabeçalho
A função a seguir toma um mapa de bits específico e cria,
dinamicamente, um cabeçalho pré-populado com todas as informações
necessárias, exceto pela variável dangling_space, que deverá ser
definida com base nos dados que serão escritos no arquivo.
huffman_header make_huffman_header(bit_map_t &bitmap) { huffman_header h; h.alphabet_size = bitmap.size(); h.letters = new huffman_pair[h.alphabet_size]; auto itr = bitmap.begin(); for(auto i = 0u; i < h.alphabet_size; i++) { h.letters[i].letter = itr->first; h.letters[i].num_bits = itr->second.size(); size_t arr_size = itr->second.size() / 8; if(itr->second.size() % 8) { arr_size++; } h.letters[i].bits = new uint8_t[arr_size]; h.letters[i].num_bytes = arr_size; { // Dump bits size_t current_byte = 0; uint8_t bit_buffer = 0u; size_t current_bit = 0; for(auto bit : itr->second) { if(current_bit == 8) { h.letters[i].bits[current_byte] = bit_buffer; bit_buffer = 0u; current_bit = 0; current_byte++; } if(bit) { bit_buffer |= ((uint8_t)(1u << (7u - current_bit))); } current_bit++; } // Dump last byte if(current_byte != arr_size) h.letters[i].bits[current_byte] = bit_buffer; // Store number of dangling bits h.letters[i].dangling_bits = 8u - current_bit; } // End of bit dump itr++; } return h; }
Destruição do cabeçalho
Quando um cabeçalho armazenado na memória não for mais necessário, é importante que esta função seja chamada para remover as alocações dinâmicas em sua constituição.
void destroy_huffman_header(huffman_header &h) { for(auto i = 0; i < h.alphabet_size; i++) { delete [] h.letters[i].bits; } delete [] h.letters; }
Mostrando o cabeçalho na tela
Esta função imprime todas as informações contidas em um certo cabeçalho, no console.
void print_header(const huffman_header &h) { cout << "flag: " << h.flag << endl << "alphabet_size: " << h.alphabet_size << endl << "dangling_space: " << (int)h.dangling_space << endl << "letters:" << endl; for(auto i = 0; i < h.alphabet_size; i++) { auto letter = h.letters + i; cout << "\tletter: "; if(isspace(letter->letter) || !isprint(letter->letter)) { cout << "0x" << std::hex << std::setfill('0') << std::setw(8) << ((int)letter->letter) << std::dec; } else { cout << letter->letter; } cout << endl; cout << "\tnum_bits: " << letter->num_bits << endl << "\tdangling_bits: " << (int)letter->dangling_bits << endl << "\tnum_bytes: " << letter->num_bytes << endl << "\tbits: "; for(auto j = 0; j < letter->num_bytes; j++) { std::bitset<8> x(letter->bits[j]); cout << x << ' '; } cout << std::dec << endl << endl; } }
Escritor de arquivo
A estrutura a seguir é uma classe, capaz de imprimir informações
bit-a-bit em um arquivo binário. A estrutura funciona utilizando uma
variável de buffer com o tamanho de um byte; cada bit a ser escrito é
armazenado no local adequado para o mesmo e, quando o byte está cheio,
este é anexado ao final de um std::vector inteiro, que espera o
momento de efetivamente escrever as informações no arquivo.
O programador fica responsável por escrever o cabeçalho (já com o espaço extra ao final ajustado) no arquivo, antes de realizar o fechamento do mesmo com a escrita efetiva das informações.
class FileWriter { private: uint8_t bit_buffer; int buffered_bits; std::ofstream stream; std::vector<uint8_t> written_bytes; void dump_bits(); public: FileWriter(); ~FileWriter(); void open(const std::string filename); bool is_open() const; void close(); void write_bits(std::vector<bool> &bits); void write_header(const huffman_header &head); int get_dangling_space() const; };
Construtor/Destrutor
O construtor da classe inicia o buffer e a contagem de bits com zeros.
FileWriter::FileWriter() { bit_buffer = 0u; buffered_bits = 0; }
O destrutor da classe realiza o fechamento do arquivo.
FileWriter::~FileWriter() { this->close(); }
Macro para dump de variável em um stream binário
O macro a seguir acelera a escrita de um certo valor em um stream de arquivo binário, reduzindo a verbosidade do código.
#define bin_write(s, x) \ s.write((const char*)&x, sizeof x)
Registro de bytes cheios
O método a seguir é um método interno que toma o buffer atualmente preenchido e coloca-o ao final do vetor de bytes a serem escritos. O buffer e a contagem de bits são, por fim, zerados novamente.
void FileWriter::dump_bits() { if(buffered_bits > 0) { written_bytes.push_back(bit_buffer); buffered_bits = 0; bit_buffer = 0u; } }
Abrir arquivo
Este método abre o arquivo informado para saída, especificando a escrita de um arquivo binário.
void FileWriter::open(const std::string filename) { stream.open(filename.c_str(), std::ios::binary); }
Predicado para informar status do arquivo
Este método informa o status de abertura do arquivo.
bool FileWriter::is_open() const { return stream.is_open(); }
Fechar arquivo
Este método fecha o arquivo binário, desde que já esteja aberto.
O fechamento do arquivo também acarreta a adição imediata de quaisquer bits no buffer que já não tenham sido adicionados ao vetor de escrita. Logo após, todos os bytes do vetor de escrita serão sequencialmente inseridos no arquivo binário, que será então fechado.
A escrita das informações textuais no arquivo binário são, portanto, feitas durante o fechamento do mesmo.
void FileWriter::close() { if(!stream.is_open()) return; dump_bits(); for(auto byte : written_bytes) { bin_write(stream, byte); } stream.close(); }
Escrever vetor de bits no arquivo
Este método toma um vetor de bits (representado como um vetor de valores booleanos, da mesma forma como são armazenados no mapa de bits) e "escreve-os" no arquivo.
Os bits informados são colocados um a um no buffer de tamanho de um byte, até que este byte esteja cheio. Quando isto ocorre, o byte é colocado no vetor interno de bytes a serem escritos no arquivo, no momento do fechamento deste.
void FileWriter::write_bits(std::vector<bool> &bits) { for(auto bit : bits) { if(buffered_bits == 8) { dump_bits(); } uint8_t proper_bit = bit ? 1u : 0u; proper_bit <<= (7 - buffered_bits); bit_buffer |= proper_bit; buffered_bits++; } }
Escrever cabeçalho informado no arquivo
Este método toma uma referência a uma estrutura do cabeçalho, e então escreve imediatamente esta estrutura no arquivo binário, caso este esteja aberto.
void FileWriter::write_header(const huffman_header &head) { if(!stream.is_open()) { return; } stream.write(head.flag, 8 * sizeof(char)); bin_write(stream, head.alphabet_size); bin_write(stream, head.dangling_space); for(auto i = 0; i < head.alphabet_size; i++) { auto pair = head.letters + i; bin_write(stream, pair->letter); bin_write(stream, pair->num_bits); bin_write(stream, pair->dangling_bits); bin_write(stream, pair->num_bytes); for(auto j = 0; j < pair->num_bytes; j++) { bin_write(stream, pair->bits[j]); } } }
Bits sobrando
Este método informa a quantidade de bits sobrando para escrita no buffer, após a última inserção de bits realizada.
int FileWriter::get_dangling_space() const { return (8 - buffered_bits); }
Leitor do arquivo
A estrutura a seguir também é uma classe, desta vez orientada à leitura de um arquivo binário bit-a-bit. Aqui também utilizamos a ideia do buffer, porém para leitura: contamos a quantidade de bits já lidos e, caso a leitura do buffer tenha se esgotado, tomamos um novo byte para o mesmo, para que a leitura possa continuar, até que o arquivo se esgote.
Fica a critério do programador obter imediatamente o cabeçalho após a abertura do arquivo, e também fica a critério do mesmo gerar o mapa de caracteres (uma inversão do mapa de bits) a partir do cabeçalho obtido. Todavia, o processo de tradução do restante do arquivo pode ser feito de forma automática por um objeto desta classe, o que inclui também a própria reescrita do arquivo-texto.
class FileReader { private: uint8_t bit_buffer; int buffered_bits; uint32_t dangling_bits; std::ifstream stream; void fetch_bits(); public: FileReader(); ~FileReader(); void open(const std::string filename); bool is_open() const; huffman_header read_header(); char_map_t make_charmap(huffman_header &h); bool translate_bits(const std::string outfile_name, const char_map_t &charmap); void close(); };
Construtor/Destrutor
O construtor da classe inicializa com zeros o buffer, a quantidade de bits não-lidos no buffer, e a quantidade de bits não-utilizados ao final do arquivo.
FileReader::FileReader() { bit_buffer = 0u; buffered_bits = 0; dangling_bits = 0u; }
O destrutor da classe fecha o arquivo.
FileReader::~FileReader() { this->close(); }
Macro para leitura de variável de um stream binário
O macro a seguir acelera a leitura de um certo valor em um stream de arquivo binário, reduzindo a verbosidade do código.
#define bin_read(s, x) \ s.read((char*)&x, sizeof x)
Leitura de novo byte
Quando todos os bits do buffer foram lidos, este método carrega um novo byte vindo do arquivo, e define a quantidade de bits que podem ser lidos como sendo igual a oito.
Caso o arquivo tenha chegado ao fim, o buffer e a quantidade de bits a serem lidos continuam nulos. Isto é um indicativo de fim-de-arquivo que será utilizado a seguir.
void FileReader::fetch_bits() { if(buffered_bits == 0) { bin_read(stream, bit_buffer); buffered_bits = 8; if(stream.eof()) { buffered_bits = 0; bit_buffer = 0u; } } }
Abrir arquivo
Este método abre o arquivo informado para entrada, especificando a leitura de um arquivo binário.
void FileReader::open(const std::string filename) { stream.open(filename.c_str(), std::ios::binary); }
Predicado para informar status do arquivo
Este método informa o status de abertura do arquivo.
bool FileReader::is_open() const { return stream.is_open(); }
Leitura de cabeçalho
O método a seguir lê um cabeçalho a partir do arquivo atualmente aberto no objeto atual. Adicionalmente, o número de bits não-utilizados ao final do arquivo é atribuído ao campo interno do objeto que armazena este valor, preparando-o para uma futura leitura de bits.
huffman_header FileReader::read_header() { huffman_header h; if(!stream.is_open()) return h; stream.read(h.flag, 8 * sizeof(char)); h.flag[7] = '\0'; if(strcmp(h.flag, "HUFFMAN")) { throw "Arquivo invalido"; } bin_read(stream, h.alphabet_size); bin_read(stream, h.dangling_space); h.letters = new huffman_pair[h.alphabet_size]; for(auto i = 0; i < h.alphabet_size; i++) { auto pair = h.letters + i; bin_read(stream, pair->letter); bin_read(stream, pair->num_bits); bin_read(stream, pair->dangling_bits); this->dangling_bits = pair->dangling_bits; bin_read(stream, pair->num_bytes); pair->bits = new uint8_t[pair->num_bytes]; for(auto j = 0; j < pair->num_bytes; j++) { bin_read(stream, pair->bits[j]); } } return h; }
Geração de mapa de caracteres
A partir de um cabeçalho carregado, este método é capaz de gerar um mapa de caracteres (mapa reverso de bits). Este mapa gerado será crucial para a tradução do arquivo binário de volta para um arquivo-texto.
char_map_t FileReader::make_charmap(huffman_header &h) { char_map_t charmap; for(auto i = 0; i < h.alphabet_size; i++) { auto pair = h.letters + i; std::vector<bool> bitvec; for(auto j = 0; j < pair->num_bytes; j++) { for(uint8_t offset = 8; offset > 0; offset--) { if((j == pair->num_bytes - 1) && (offset <= pair->dangling_bits)) { break; } uint8_t bit = pair->bits[j] & ((uint8_t)(1u << (offset - 1))); bitvec.push_back(bit ? true : false); } } charmap[bitvec] = pair->letter; } return charmap; }
Tradução de arquivo
O método a seguir traduz o arquivo binário atualmente aberto no objeto para um arquivo-texto, localizado no parâmetro informado. Este método também recebe uma referência a um mapa de caracteres (mapa reverso de bits) que será utilizado na tradução.
Este método tenta abrir um novo arquivo-texto localizado em
outfile_name, e então escreve letra a letra traduzida, de acordo com o
mapeamento dos bits lidos.
A tradução assume que o cabeçalho do arquivo já tenha sido lido, e envolve ler bit a bit do restante do arquivo para dentro de um vetor de bits, representado como um vetor booleano. Assim que o vetor passa a ter um correspondente entre as chaves do mapa de caracteres, o caractere correspondente a este vetor no mapa é escrito no arquivo-texto, e o vetor booleano é limpado para uma novo recebimento de bits.
O processo de tradução é encerrado quando o arquivo acaba ou quando
todos os bits úteis do último byte do arquivo já foram traduzidos. No
segundo caso, o campo interno dangling_bits determina a quantidade
máxima de bits que serão lidos do último byte do arquivo.
bool FileReader::translate_bits(const std::string outfile_name, const char_map_t &charmap) { std::ofstream ofs(outfile_name.c_str()); if(!ofs.is_open()) { return false; } std::vector<bool> read_bits; while(stream.good()) { fetch_bits(); if(buffered_bits == 0) { break; } if(stream.peek() == EOF && buffered_bits == dangling_bits) { break; } uint8_t current = bit_buffer & ((uint8_t)(1u << (buffered_bits - 1))); read_bits.push_back(current ? true : false); buffered_bits--; auto itr = charmap.find(read_bits); if(itr != charmap.end()) { ofs << itr->second; read_bits.clear(); } } ofs.close(); return true; }
Fechamento de arquivo
Este método fecha o arquivo de entrada.
void FileReader::close() { if(stream.is_open()) { stream.close(); } }
Ponto de entrada
As construções a seguir determinam o ponto de entrada do programa, isto é, a seção do mesmo por onde o programa começa a ser executado, bem como elementos importantes para a interação com o usuário.
Variáveis globais
As variáveis a seguir determinam valores relacionados às entradas do programa via linha de comando. O programa deve ser configurado através de argumentos do console, que modificarão estes valores globais.
// Nomes de entrada e saída padrão para // compressão. static std::string output_filename = "a.out"; static std::string input_filename; // Opções de argumentos static bool extract = false; static bool dbg_output = false; static int dbg_type = 0; static bool dbg_bits = false; static bool dbg_header = false;
Texto de cabeçalho
A função a seguir mostra um cabeçalho de informações do programa, que será impresso mediante pedido do usuário ou conveniência.
void show_info() { cout << "Huffman Compress/Decompress v1.0" << endl << "Copyright (c) 2020 Lucas S. Vieira" << endl << "Este codigo e distribuido sob a licenca MIT." << endl << "Veja o arquivo LICENSE para mais detalhes." << endl << endl; }
Texto de ajuda
Esta função mostra o texto de ajuda da aplicação, exibindo opções que podem ser repassadas via argumentos da linha de comando. Veja que algumas opções só são mostradas caso o programa tenha sido compilado com suporte às mesmas.
void show_help() { cout << "Uso:" << endl << endl << "\thuffman [opcoes...] <entrada> [-o <saida>]" << endl << endl << "Argumentos da linha de comando:" << endl << endl << " <entrada> \tArquivo-texto a ser operado." << endl << endl << " -o <saida> \tArquivo a ser escrito apos a" << endl << " \tapos a operacao (opcional)." << endl << endl << " -x \tExtrai o arquivo de entrada para a" << endl << " \tsaida informada." << endl << endl << " --dot \tMostra codigo GraphViz da arvore" << endl << " \tde Huffman." << endl << endl #ifdef USE_FEH << " --image \tMostra a arvore de Huffman no feh." << endl << endl #endif // USE_FEH #ifdef USE_XDOT << " --xdot \tMostra arvore de Huffman no xdot." << endl << endl #endif // USE_XDOT << " --freq \tMostra a tabela de frequencias." << endl << endl << " --bits \tMostra o mapa de bits para o " << endl << "alfabeto." << endl << endl << " --head \tMostra o cabecalho do arquivo" << endl << " \tapos comprimido." << endl << endl << " --help \tMostra este texto de ajuda." << endl << endl << " --info \tMostra informacoes do programa e " << endl << " \tencerra." << endl << endl; }
Processo de compressão
A função a seguir realiza a operação de compressão de um arquivo-texto passo-a-passo, utilizando as estruturas programadas anteriormente.
int huffman_compress(void) { // Abra o arquivo std::ifstream ifs(input_filename.c_str()); if(!ifs.is_open()) { cerr << "Impossivel abrir o arquivo de entrada " << input_filename << endl; return 1; } // Gere mapa de frequências freq_map_t freq_map = build_frequency_map(ifs); ifs.clear(); ifs.seekg(0); // Imprime mapa de frequências, se necessário if(dbg_output && dbg_type == 3) { show_freq_map(freq_map); ifs.close(); return 0; } // Construa a árvore de Huffman auto root = build_huffman_tree(freq_map); // Mais ferramentas de debug, se utilizadas if(dbg_output) { int ret = 0; switch(dbg_type) { case 0: print_graphviz(root); break; #ifdef USE_GRAPHVIZ #ifdef USE_FEH case 1: show_graphviz(root); break; #endif // USE_FEH #ifdef USE_XDOT case 2: show_graphviz(root, true); break; #endif // USE_XDOT #endif // USE_GRAPHVIZ default: cerr << "Opcao de visualizacao nao-suportada" << endl; ret = 1; break; } ifs.close(); destroy_tree(root); return ret; } // Construa o mapa de bits para os caracteres. // Este mapa de bits deverá ser salvo // para descompressão bit_map_t bitmap = make_bit_map(root); // Destrua a árvore destroy_tree(root); if(dbg_bits) { print_bitmap(bitmap); ifs.close(); return 0; } // Crie o cabeçalho do mapa de bits huffman_header h = make_huffman_header(bitmap); if(dbg_header) { print_header(h); ifs.close(); return 0; } // Abra o arquivo de saída FileWriter fw; fw.open(output_filename); if(!fw.is_open()) { cerr << "Erro ao abrir arquivo de saida " << output_filename << endl; destroy_huffman_header(h); ifs.close(); return 1; } // Reescreva o arquivo passo-a-passo while(ifs.good()) { char c = ifs.get(); fw.write_bits(bitmap[c]); } // Feche, finalmente, o arquivo de entrada ifs.close(); // Recupere o espaço extra ao final, armazene no cabeçalho h.dangling_space = fw.get_dangling_space(); // Escreva o cabeçalho fw.write_header(h); // Feche o arquivo, escrevendo as informações fw.close(); // Destrua o cabeçalho destroy_huffman_header(h); return 0; }
Processo de extração
A função a seguir realiza a operação de extração de um arquivo binário passo-a-passo, utilizando as estruturas programadas anteriormente.
int huffman_extract(void) { if(dbg_output) { cerr << "O processo de extracao nao remonta uma " << "arvore ou mapa de frequencias que possam " << endl << "ser visualizados" << endl; return 1; } // Abra o arquivo de entrada FileReader fr; fr.open(input_filename); if(!fr.is_open()) { cerr << "Impossivel abrir o arquivo de entrada " << input_filename << endl; return 1; } // Crie e popule o cabeçalho huffman_header h; try { h = fr.read_header(); } catch(const char* &e) { cerr << "Erro ao ler o arquivo " << input_filename << ": " << e << endl; fr.close(); return 1; } if(dbg_header) { print_header(h); destroy_huffman_header(h); fr.close(); return 0; } // Cria mapa de caracteres // (Mapa reverso de bits) char_map_t charmap = fr.make_charmap(h); destroy_huffman_header(h); if(dbg_bits) { print_charmap(charmap); fr.close(); return 0; } // Reescreva o arquivo na saida if(!fr.translate_bits(output_filename, charmap)) { cerr << "Erro ao traduzir o arquivo " << input_filename << endl; fr.close(); return 1; } fr.close(); return 0; }
Resolução de argumentos do console
Esta função toma os argumentos do console do programa e resolve-os, modificando as variáveis globais segundo necessário.
int resolve_args(int argc, char **argv) { for(int i = 1; i < argc; i++) { if(!strcmp(argv[i], "-o")) { i++; if(i >= argc) { cerr << "Nome do arquivo nao informado" << endl; return 1; } output_filename = argv[i]; } else if(!strcmp(argv[i], "-x")) { extract = true; } else if(!strcmp(argv[i], "--dot")) { dbg_output = true; dbg_type = 0; } else if(!strcmp(argv[i], "--image")) { dbg_output = true; dbg_type = 1; } else if(!strcmp(argv[i], "--xdot")) { dbg_output = true; dbg_type = 2; } else if(!strcmp(argv[i], "--freq")) { dbg_output = true; dbg_type = 3; } else if(!strcmp(argv[i], "--bits")) { dbg_bits = true; } else if(!strcmp(argv[i], "--head")) { dbg_header = true; } else if(!strcmp(argv[i], "--help")) { show_help(); return 0; } else if(!strcmp(argv[i], "--info")) { show_info(); return 0; } else { // Caso haja um nome de saída, colete-o input_filename = argv[i]; } } if(input_filename == "") { cerr << "Informe um arquivo a ser operado." << endl; return 1; } else if(input_filename == output_filename) { cerr << "Usar o mesmo arquivo para entrada e " << "saida nao e recomendado" << endl; return 1; } return 0; }
Função principal
Esta é a função principal (main) da aplicação. Ela é responsável por
invocar a resolução de argumentos e invocar os processos de compressão
e extração.
int main(int argc, char **argv) { // Parsing de argumentos do console // Devemos pelo menos um argumento. Lembrando // que argv[0] é a linha de execução do aplicativo. if(argc <= 1) { show_info(); show_help(); return 1; } if(resolve_args(argc, argv)) { return 1; } if(!extract) { return huffman_compress(); } else { return huffman_extract(); } }
Apêndices
Teste tipográfico
Os arquivos a seguir são testes tipográficos simples, criados para testar os algoritmos em pequenas amostras.
O primeiro teste possui uma quantidade reduzida de letras.
abba is bad.
O segundo teste repete pelo menos uma vez cada caractere de letras da tabela ASCII.
The quick brown fox jumps over the lazy dog.
O terceiro teste repete pelo menos uma vez cada caractere acentuado da língua portuguesa. Isto também envolve codificação específica de arquivos, mas aqui tratamos todos os elementos textuais com o tamanho de um único byte.
À noite, vovô Kowalsky vê o ímã cair no pé do pingüim queixoso e vovó põe açúcar no chá de tâmaras do jabuti feliz.
Lorem ipsum simples
O texto "Lorem ipsum" é um texto sem sentido, gerado automaticamente em latim. Este texto normalmente é utilizado para testes tipográficos de layout e enquadramento.
Aqui, utilizamos um parágrafo gerado automaticamente para testar a distribuição de caracteres ASCII para compressão.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Pellentesque dictum enim a metus ullamcorper, at vestibulum nunc semper. Phasellus ornare eros imperdiet purus cursus accumsan. Nunc urna neque, porta ac.
Lorem ipsum complexo
O texto abaixo compreende cinco parágrafos automaticamente gerados de "Lorem ipsum", assim como o texto anterior. Pelo fato de ser mais extenso, começamos a ver menor ocupação de espaço em disco após a compressão deste texto.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed venenatis, libero a mattis imperdiet, libero tortor fermentum arcu, et bibendum sem purus et felis. Sed sodales purus sed velit pulvinar lacinia. Maecenas condimentum, est eu consequat interdum, felis nibh tincidunt massa, ac ornare mi nulla at felis. Praesent quis sagittis sem. Pellentesque nec nunc at enim porttitor fringilla. Phasellus tristique, leo sollicitudin vehicula euismod, magna dui cursus lacus, sit amet pharetra urna eros sed dui. Ut porttitor dui eu lacus fringilla fermentum. Morbi id sem lacinia, congue orci eu, efficitur magna. Nam in diam ut urna rhoncus malesuada id non sem. Nullam in vestibulum velit. Curabitur facilisis ultricies diam, eget mattis odio hendrerit eget. Donec lacinia, justo non luctus cursus, velit augue vestibulum diam, eu congue tortor arcu vitae eros. Duis et diam aliquam nulla congue fermentum. Phasellus consectetur lorem elit, sed convallis sem suscipit non. Suspendisse et nulla felis. Donec ut velit nisi. Donec eu tempus felis, eu laoreet dolor. Fusce facilisis nisi id condimentum ultricies. Phasellus mattis tempor erat, quis vulputate neque pharetra eu. Nunc ligula purus, consectetur et augue vulputate, accumsan semper dolor. Maecenas finibus quis tortor vitae cursus. Pellentesque orci sem, accumsan ac dolor non, dignissim vehicula odio. Vivamus pulvinar dictum sem, quis ullamcorper nibh tincidunt eget. Donec ut nibh enim. Maecenas ut dolor elit. Donec ultricies sollicitudin est vitae eleifend. Ut eleifend eu mauris eu pretium. Sed tincidunt fermentum sem sed varius. Nullam quis mi varius, molestie diam porttitor, viverra libero. Proin interdum mi nulla, id varius ligula laoreet vel. Nullam varius fermentum orci, in eleifend urna. Curabitur nibh dolor, pharetra at leo nec, egestas condimentum sem. Sed eu orci eget elit cursus porta sed vel purus. Mauris finibus eget turpis sed bibendum. Cras luctus neque ac purus lacinia, laoreet fermentum risus sodales. Morbi est est, congue et mollis in, hendrerit nec justo. Mauris accumsan auctor ex, eu porta metus efficitur vitae. Integer auctor id massa ut sodales. Curabitur dolor sapien, vehicula nec magna ut, efficitur posuere dolor. Pellentesque habitant morbi tristique senectus et netus et malesuada fames ac turpis egestas. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia Curae; Etiam eget eleifend mauris. Vestibulum id blandit est. Cras dictum ligula at lacinia facilisis. Etiam facilisis magna nisi, a egestas lorem lobortis at. Vestibulum laoreet, urna sit amet luctus ornare, ex sem pretium nisi, iaculis pharetra arcu ipsum nec massa. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Proin et ipsum velit.
Makefile
O código a seguir constitui um arquivo Makefile para a compilação do arquivo em questão.
Este arquivo Makefile garante que o programa seja compilado com a especificação de 2014 da linguagem C++, e também consulta o sistema pela existência dos programas externos que podem ser utilizados. Caso estes programas não existam no sistema, o suporte a eles será removido durante a compilação.
CXX := clang++ --std=c++14 CXXFLAGS := -Wall -pedantic -g -O2 EXTRA_FLAGS := OUTFLAG := -o BINARY := huffman SRC := huffman.cpp # Ferramentas externas DOT := /usr/bin/dot XDOT := /usr/bin/xdot FEH := /usr/bin/feh # Teste pela existência do binário GraphViz ifeq ($(shell test -s $(DOT) && echo -n ok),ok) EXTRA_FLAGS += -DUSE_GRAPHVIZ endif # Teste pela existência do binário xdot ifeq ($(shell test -s $(XDOT) && echo -n ok),ok) EXTRA_FLAGS += -DUSE_XDOT endif # Teste pela existência do binário feh ifeq ($(shell test -s $(FEH) && echo -n ok),ok) EXTRA_FLAGS += -DUSE_FEH endif all: $(BINARY) $(BINARY): $(SRC) $(CXX) $(CXXFLAGS) $(EXTRA_FLAGS) $^ $(OUTFLAG) $@ clean: rm -f $(BINARY)
Sobre o licenciamento
Todo o código deste projeto é licenciado sob a licença MIT. Isto significa que qualquer pessoa pode reutilizar este programa para qualquer circunstância, inclusive comercial, desde que a cópia ainda possua esta mesma licença ou uma compatível, e que o criador do programa seja isentado de quaisquer responsabilidades para com o uso do mesmo.
Licença MIT
O texto abaixo é uma cópia completa da licença do software deste artigo.
MIT License Copyright (c) 2020 Lucas Vieira Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Notas de Rodapé:
``Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do.''
Especificamente, std::function<bool(huffman_node_t*, huffman_node_t*)>.
Assumimos aqui que o stream seja válido e esteja aberto.